개요
사용자가 크롬과 같은 브라우저를 열어 주소창에 www.google.com을 입력하면 구글 사이트에 접속할 수 있다.
본 글에서는 구글이 사용자에게 웹페이지를 제공하는 개괄적인 내용을 다룬다.
보통 웹페이지를 제공하는 컴퓨터를 Web Server(웹 서버)라고 부른다. 경우에 따라 Web Server가 아닌 Web Application Server를 사용할 수도, 둘 다 사용할 수도 있다.
웹 서버 (Web Server)
웹 서버는 정적 페이지를 제공한다. 대표적인 프레임워크로는 Apache, NginX가 있다.
웹페이지를 예쁘게 보여주는 것은 클라이언트에 설치된 브라우저의 역할이지, 웹서버는 그저 웹페이지를 구성하는 코드를 보내줄 뿐이다.
웹 서버에게 파일을 요청하자
정적 페이지
html, css, js와 같은 파일들로 이뤄진 페이지다. 이미 서버 컴퓨터에 저장되어 있는 파일 그대로 보내준다.
URL
URL을 이용하면 쉽게 웹서버로부터 파일을 받아올 수 있다.
`[Protocol]://[Domain or IP Address]:[Port]/[Path]?[Parameters]`
`[Port]`와 `[Path]` 사이에 있는 `/`는 Web Root Path라고 부른다. 웹 서버가 제공하는 디렉토리 중 최상위 디렉토리라고 보면 된다.
즉, 이 Web Root Path보다 상위에 있는 디렉토리 또는 파일에는 접근할 수 없다. 가령 `../`를 사용하더라도 말이다.
Well-known Port
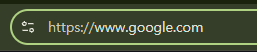
분명 `[Domain or IP Address]` 뒤에는 `[Port]`가 와야한다고 적혀 있다. 하지만 사진에는 https://www.google.com 뒤로 어떠한 글자도 붙어있지 않다.
바로 443이라는 포트 번호가 생략됐기 때문이다. 웹 서버는 보통 사용하는 프로토콜이 `HTTP`라면 80번 포트를, `HTTPS`라면 443번 포트를 사용한다. 어차피 대부분의 서버가 정해진 포트로 사이트를 제공한다면 생략하는 편이 보기 좋다. (물론, 서버가 다른 포트를 열었다면 해당하는 포트를 명시적으로 적어줘야 문제없이 접속할 수 있다.)
사진의 경우에는 `:443`이 생략된 것이다. 실제로 `:443`을 붙이고 접속하면 구글 검색창이 정상적으로 뜰 것이다.
index.html
`[Path]`를 살펴보자. 최상위 디렉토리의 경로가 파일을 의미하는 것은 아닐 것이다. 하지만 웹페이지가 정상적으로 불러와진다. 그렇다면 `[Path]`도 생략된 걸까?
생략된 것으로 생각해도 큰 문제가 없겠지만 정확히는 생략된 것은 아니다. `[Path]`를 비워뒀을 때 웹서버에서 자동으로 제공해줄 파일이 정해져있다. 보통 이러한 파일의 이름을 index라고 한다. 대부분 HTML로 작성되므로 정확한 파일의 이름은 index.html로 생각하면 된다.
실제로 Apache 또는 NginX 같은 웹서버 프로그램을 실행하면 `/var/www/html/` 밑에 `index.html`이라는 파일을 제공하고 있는 모습을 볼 수 있을 것이다.
HTTP Method
HTTP에는 서버에 요청을 보낼 때 Method를 지정해야 한다.
대표적으로 `GET`, `POST`, `PUT`, `PATCH`, `DELETE`가 있다. 이 외에는 `HEAD`, `OPTIONS`, `CONNECT`, `TRACE`가 있다. 이 글에서는 대표적인 다섯 개의 Method만 다룬다.
- `GET`: 파일을 요청하는 Method이다.
- `POST`: 무언가를 등록할 때 사용하는 Method이다.
- `PUT`: 데이터를 수정하는 Method이다.
- `PATCH`: 마찬가지로 데이터를 수정하는 Method이다.
- `DELETE`: 데이터를 삭제하는 Method이다.
멱등성 (Idempotence)
`PUT`과 `PATCH`가 당연히 똑같은 역할을 하지는 않는다. 약간의 차이가 존재한다.
멱등성이란 같은 일을 여러번 수행했을 때 결과가 같음을 의미한다. `PUT`과 `PATCH`는 이 멱등성의 특성에서 차이가 난다.
`PUT`은 멱등성이 성립하지 않는 반면, `PATCH`는 성립한다. 회원정보에서 비밀번호를 수정하는 과정을 예로 들어보겠다.
- `PUT`을 사용하는 경우
클라이언트는 수정될 정보로 { "password": "new_password" } 를 body에 담아 전달했다. 하지만 수정된 회원 정보 결과를 보니, "password"는 원하는대로 바뀐 것을 확인할 수 있었지만 "id"는 NULL이 되어버렸다. - `PATCH`를 사용하는 경우
클라이언트는 수정될 정보로 { "password": "new_password" } 를 body에 담아 전달했다. 예상했던대로 "id"는 원래 값으로 유지가 되고, "password"만 수정된 것을 확인할 수 있다.
`PUT`을 사용하면 입력하지 않은 field들이 NULL 또는 Default 값으로 변경돼버릴 수 있다. 따라서 `PUT`을 사용할 땐 다른 field들의 값들도 채워줄 필요가 있다.
GET & POST
`GET`과 `POST` 둘 다 특정한 페이지를 요청하기 위해 사용할 수 있다. 당연히도, 이 둘 사이에 약간의 차이가 존재한다.
// GET 방식
<?php
<form action="login_proc" method="GET">
<input type="text" name="id">
<input type="password" name="pw">
<input type="submit" value="Login">
</form>
?>// POST 방식
<?php
<form action="login_proc" method="POST">
<input type="text" name="id">
<input type="password" name="pw">
<input type="submit" value="Login">
</form>
?>둘 다 login_proc으로 넘어가 로그인을 처리시키는 php 코드다. 차이점은 `GET`이냐 `POST`이냐 뿐이다. 하지만 이 다음 과정에서 URL 부분에서 차이가 크게 난다.


`GET`은 URL의 `[Parameters]` field에 input을 전부 포함시킨다. 사용자의 민감한 정보가 URL에 그대로 담기는건 절대 유쾌한 일이 아니다. 따라서 `POST` 방식이 이런 보안적인 면에서는 좀 더 낫다고 볼 수 있다.
웹 어플리케이션 서버 (Web Application Server; WAS)
웹 어플리케이션 서버는 동적 페이지를 주로 제공한다. 대표적인 프레임워크로는 FastAPI, Tomcat, Spring boot 등이 있다.
동적 페이지
웹 어플리케이션 서버는 웹 서버와 다르게 동적 페이지를 제공한다. 동적 페이지는 파일을 그대로 보내주는 것이 아닌, 서버에서 클라이언트의 요청에 따라 생성된 페이지를 보내주는 페이지다. 때문에 응답 속도는 조금 더 느리지만 유연하게 제공이 가능하다.
Web Server - Web Application Server
웹 서버, 웹 어플리케이션 서버 둘 다 사용하는 경우에는 클라이언트의 요청에 좀 더 능동적으로 대처할 수 있다.
요청 처리 과정
웹 서버는 정적 페이지, 웹 어플리케이션 서버는 동적 페이지를 처리한다고 상술했다. 그럼 클라이언트의 요청이 들어왔을 때 어떻게 요청을 처리하는지 단계별로 보겠다.
정적 페이지의 경우
- `[Client → Web Server]`: 파일 요청
- `[Web Server → Client]`: 파일 제공
동적 페이지의 경우
- `[Client → Web Server]`: 파일 요청
- `[Web Server → Web Container(WAS)]`: 동적페이지 요청
- `[WAS → Web Server]`: 동적 페이지 제공
- `[Web Server → Client]`: 파일 제공
Web Server의 또다른 역할
웹 서버는 그냥 WAS와 함께 페이지를 제공할 수 있지만, 다른 역할로도 사용이 가능하다. WAS의 부담을 덜어주고 보안을 강화하는 Load Balancer, Reverse Proxy Server가 있다.
Load Balancer
클라이언트의 요청은 웹 서버가 받고, 웹 서버가 여러 개의 웹 어플리케이션 서버로 할 일을 나눠준다. 즉, 부하 분산의 목적이다. 하나의 웹 어플리케이션 서버에 요청이 너무 몰리지 않도록 하기 위함이다. 또한, 클라이언트와 웹 어플리케이션을 떨어뜨려 놓음으로써 보안적인 측면에서도 좋다.
Reverse Proxy Server
웹 서버는 Load balancer가 아닌 reverse proxy server의 용도로도 사용할 수 있다. Forward Proxy Server(일반적인 개념의 프록시 서버)의 서버측 버전이라고 보면 된다. 클라이언트의 요청을 받고서는 자신이 클라이언트가 된 것처럼 웹 어플리케이션 서버에 요청을 하고 파일을 받아온다. 그 뒤, Reverse Proxy Server는 클라이언트에게 받아온 파일을 전달한다. 또한 프록시의 기능도 있다. 요청이 자주 발생하는 파일에 대해서는 웹 서버가 갖고 있다가 클라이언트에게 바로 전달해줄 수 있다.
'Study > with normaltic' 카테고리의 다른 글
| SegFault CTF - 5주차 - 1 (0) | 2025.05.06 |
|---|---|
| SegFault CTF - 4주차 (0) | 2025.04.24 |
| 로그인 유지: 쿠키 & 세션 (0) | 2025.04.23 |
| PHP와 MySQL (0) | 2025.04.16 |
| 간단한 로그인 페이지 (1) | 2025.04.08 |